So, recently, I’m playing in someone else’s codebase, and I need to use their code to create a new Docker image that I can use for myself elsewhere. Their thin base image doesn’t have all my usual ML dependencies, so I need to extend the image. When I try, it blows up with an “Unknown compiler” message. With some legwork I learn that sklearn depends on scipy, and scipy needs to be compiled from source (and has for years now), and that thin base image doesn’t have the compiler. So I move to a non-default base image, and all is well.
Then I notice something I can’t explain, which I never would have noticed if I hadn’t been in this codebase. I had set Python to 3.9 using pyenv. I’m using pipenv --three to create a Python 3 Pipfile and then pipenv install to add some dependencies to it. (That’s all wrapped in a build script, because that’s how the codebase works, but that’s all the build script is doing.) But when I cat the Pipfile, the environment I just created is using Python 3.10, not 3.9! My mind is blown. I’ve never really used pipenv before… but I had a deeply rooted expectation that pipenv --three would use python3 --version for building the Pipfile. And clearly, it did not.
I read the pipenv docs and don’t see anything obviously relevant.
I do some internet searches. No answer.
I figure the explanation has to be obvious to anyone who actually has some pipenv experience – so I ask around. None of my usual suspects have pipenv experience either.
Then I have my epiphany. ChatGPT was just recently officially corporately blessed. This is the perfect question to use with ChatGPT – I can learn about pipenv, and I can use this to demonstrate how ChatGPT might help developers at the next engineering department sprint demo. (A good number of our developers are using Python professionally for the first time, in a codebase that extensively uses pipenv, and have not yet tried any LLMs – I like the odds of a sprint demo on this topic actually being useful for the audience.) So, I spend a few minutes composing a very careful message with an SSCCE and everything:
I need help making sense of my interactions with pipenv. I think I am creating a
Python 3.9 environment and installing packages into it, and then freezing that as
a Pipfile. But when I check the Pipfile, it shows 3.10 as my frozen environment.
Here's my shell interactions:
pipenv global 3.9
pipenv --three
python --version # output: 'Python 3.9.13'
pipenv install $pkg
cat Pipfile | grep python_version # output: 'python_version = "3.10"'
How does pipenv decide which version of Python to use? Be super succinct.
ChatGPT gives me a lovely (but still verbose) response, whose first and penultimate lines are entirely correct and ultimately all I need: “When you run pipenv --three, pipenv creates a new virtual environment using the latest version of Python that you have installed on your system. To create a virtual environment using Python 3.9, you can use pipenv --python 3.9 instead of pipenv --three.” Ah hah!
I ask it a bunch of related pipenv sense-making questions to get myself smarter on pipenv. ChatGPT gets most of my questions beautifully, perfectly, verifiably right. Then, harkening back to my “sklearn requires scipy requires a compiler” trouble from earlier, I ask a trickier (pure pip) question: “can I pip install precompiled binaries of scikit-learn and its upstreams instead of building from source?” ChatGPT’s answer is so wrong it’s painful: “Yes, there are precompiled binary versions of scikit-learn that you can install instead of building from source. You can try installing the precompiled binary version of scikit-learn by running the following command: pip install -U scikit-learn”. No, sorry, definitely not. In no Python world can you get a precompiled binary for all dependencies by upgrading a downstream user library written in Python. That’s a farcical statement.
And so I shared the story and take-aways at this sprint demo this week:
pyenv and pipenv work together… mostly.
pipenv will ignore your pyenv!
You get your very own Star Trek Computer now… it’s better than a rubber duck, and it’s the kindest, least judgmental coworker ever. (But it’s not your actual coworker; don’t send confidential or sensitive information.)
Recently I broke a Python web service by adding a new library to the backend. I was floored, because there was no reason that library should have affected anything in the service layer. But of course the computer wasn’t wrong. There was a reason. And figuring it out meant I got to take a deep dive into the coherent cloud of strange practices that is Python web services.
My misbehaving Python service follows all the established best practices. Its public face is an nginx server that accepts public HTTP(S) connections from clients. That nginx server talks to an internal gunicorn server. The gunicorn server is a Python WSGI server that handles many simultaneous HTTP connections; it translates from HTTP connections to Python logic. The gunicorn server loads and serves a Flask application. The Flask application encapsulates the application logic. It links particular web paths in the application to the Python code that calculates the response payloads. All good, and nothing strange here.
The bug first manifested as POSTs responding with empty replies to clients on my local machine. The server log said there was a segmentation fault – signal 11, SIGSEGV. A segmentation fault means a process is accessing memory that does not belong to it:
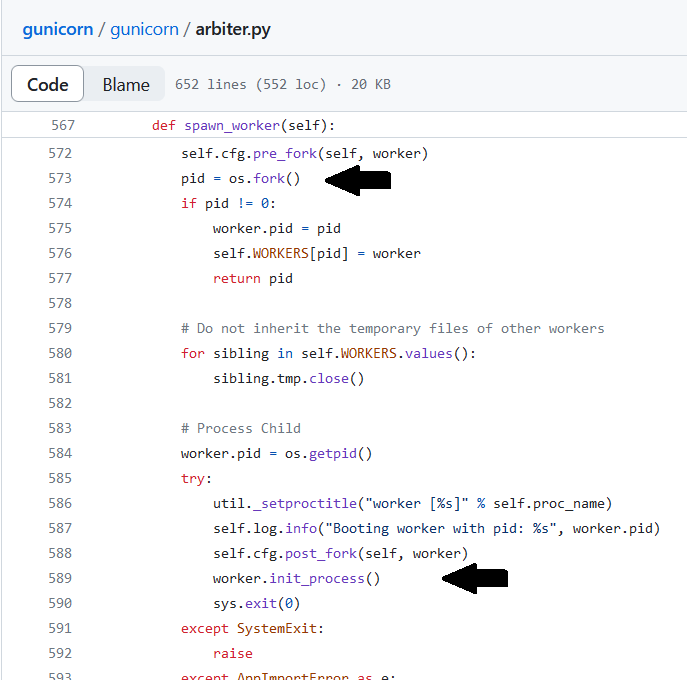
[2022-01-20 11:18:26 -0800] [75979] [INFO] Starting gunicorn 20.1.0
[2022-01-20 11:18:26 -0800] [75979] [INFO] Listening at http://0.0.0.0:8080 (75979)
[2022-01-20 11:18:26 -0800] [75979] [INFO] Using worker: sync
[2022-01-20 11:18:26 -0800] [75987] [INFO] Booting worker with pid: 75987
The process has forked and you cannot use this CoreFoundation functionality safely. You MUST exec().
Break on __THE_PROCESS_HAS_FORKED_AND_YOU_CANNOT_USE_THIS_COREFOUNDATION_FUNCTIONALITY___YOU_MUST_EXEC__() to debug.
[2022-01-20 11:18:26 -0800] [75979] [WARNING] Worker with pid 75987 was terminated due to signal 11
[2022-01-20 11:18:26 -0800] [75989] [INFO] Booting worker with pid: 75989
I grumbled to myself, thinking “What kind of ridiculous system calls fork without exec?!? Surely anything as widely used as gunicorn behaves in reasonable ways. This error message must be a red herring.”
Yes, gunicorn calls fork without exec. They call it a "pre-fork worker model".
Well, then I read the gunicorn source code. Calling fork without exec is exactly what gunicorn does. It forks, then the child initiates the core of the application. No exec to be found, which means the child inherits all the parent’s memory. The child nods to resource cleanup by closing a bunch of file pointers – but the memory is shared with the parent. (And kind of oddly, each child separately reinitializes all the application state by default – rather than initializing in the parent, forking, and letting all the children share all the read-only memory. You can get the second behavior, but you have to actively set preload_app=True.)
I verified that the fork-without-exec behavior was the root problem in a couple more ways. First I ran the application bare, as a single process, with no gunicorn. Flask alone didn’t segfault, which reinforced the idea of gunicorn’s fork behavior as the culprit. Then I checked the Mac Console (a useful tool that I learned about during this investigation!) for Crash Reports, and it also showed the fault with the message “crashed on child side of fork pre-exec”. So, yep, fork-without-exec clearly implicated.
So then I instrumented the code. I traced the segmentation fault to the line where it occurred. The bad memory access occurred when the new library used the Google Cloud Storage client for a download operation:
self.gcs_client.download_blob_to_file( ... )
Now I finally had enough clues to start to put it together. It seems the GCS client was being created before the fork – before worker.init_process() ever ran, in fact! Then, when the child worker tried to actually use the GCS client, it segfaulted, because the GCS client was in parent memory rather than child memory. I hypothesized that the SIGSEGV occurred because Apple’s CoreFoundation OS framework disallows children using their parent’s memory as part of its ban on “fork without exec”. (I also figured that if the GCS client had been created only in the child, there would be no issue. From the child’s perspective, its process is unique and alone; apart from its pid value, the child is unaware of any multiprocessing. That said, I had never heard of CoreFoundation before this bug, so it’s quite possible CoreFoundation works a different way.)
Summarizing my understanding of the situation to this point:
The GCS storage client is created in gunicorn’s parent process.
The GCS storage client relies on some library that is compiled specifically for Mac. (pip and other package managers seamlessly choose the right binary wheel for each system, and will compile on the user’s local machine for a source distribution as needed.) Anything compiled specifically for Mac uses CoreFoundation for all the very basic operations, including URLs and stream sockets.
The gunicorn server process forks – but it doesn’t exec. Fork-without-exec is a deliberate design decision by gunicorn; it seems like gunicorn wants to make bad code with memory leaks and other issues more stable.
A POST request comes in. Gunicorn hands it to a worker, which is a child. As the worker handles the request, it tries to use that CoreFoundation functionality. Rather than getting copy-on-write semantics for CoreFoundation functionality in the parent, we get a SIGSEGV. (All fork-without-exec is potentially unsafe, so Apple blocks it since Catalina. I understand the reasoning thusly: It is impossible to guarantee that the parent is not a thread itself. If the parent is a thread, then from the point of view of the child, all its peer threads were violently murdered, and so they will never release any held locks – including important locks for the child, like locks on malloc. So, better to avoid this entire issue and instead force the entire memory of the child to be replaced via exec.)
The worker dies (it can’t handle the signal). The gunicorn parent manager spawns another child worker. But the new child has the same memory configuration, and it is also unable to handle requests.
The application is completely broken.
(This is what I pieced together. It’s my first foray into some of this tech, though – please reach out with corrections and other explanations!)
That makes sense as far as it goes. But now I had a new mystery: why would that GCS client be created before the fork? The GCS client was used deep in the bowels of request handling within the application. But the parent? That’s gunicorn. Gunicorn is a webserver. There’s no reason for application code to be executed when gunicorn starts….
At this point, I decided to tackle the problem from the other direction. I started building a very tiny version of the application entirely from scratch. Just Flask, gunicorn, and the new library functionality? No segfault. Just Flask, gunicorn, and the application’s use of the new library functionality? No segfault. Then I tried to introduce the application’s gunicorn configuration file to the mix. The system segfaulted instantly.
Reviewing the Python web service’s gunicorn config, the mystery finally became clear. The config file is in Python. The first few lines of the gunicorn config file looked like this:
fromosimport environ
fromapplication_library.application_pathimport PORT
bind =":"+str(PORT) # port to use for application
The service layer was importing the application!
When gunicorn “read” this config, it actually executed the config. (I find “execution” to be a very odd pattern to use for a config file, but whatever; this is how gunicorn works.) As soon as gunicorn executed the line from application_library.application_path import PORT, gunicorn also executed the Python file application_library.application_path, because “execute on import” shenanigans are core to how Python works: when Python first imports a file, it executes everything in the file and attaches it to the module’s scope (check out dir(sys.modules["$moduleName"]) to see this in action).
That PORT import has massive side-effects, because the Flask app object was defined in that same file. Flask’s pattern for creating applications is to include app = Flask(__name__) as a plain line in a Python file. That line isn’t wrapped in a class, or in any kind of conditional. It’s just a top-level, unindented statement. As a result, when we imported PORT from a file that also included app = Flask(__name__), the whole application immediately sprung into being. Even down to a GCS client deep in the bowels of the application.
So that little throwaway PORT import? It was probably introduced to guarantee that the default ports used by a Flask server and a gunicorn server always matched (it might have even been introduced by me – I gave up git blame after tracing the refactor history for a few minutes). But that import statement also unwittingly caused the entire application to be created pre-fork, in the server – which broke the whole application on strict Macs.
Once tracked down, the fix was thankfully simple. I replaced that too-DRY reference to PORT with more duplication. I defined the default port number independently in Flask and gunicorn so there would be no dependency between the service layer and the application layer:
bind =f":{os.environ.get('PORT', 8080)}"# port to use for application
With this change, the application does not exist until worker.init_process(). The segmentation fault is gone.
(It’s unlikely I’d have noticed this bug if I had only been testing on Linux servers. I prefer the lower overhead of local testing when possible, but this is a good reminder that the platform sometimes does still matter. Cross-platform code is hard.)
My takeaway from this debugging experience is “weirdness propagates from initial decisions”. Python, gunicorn and Flask mostly play nice together, but it’s because they’re built on each others’ crazy (and a lot of eyes).
The chains I see are:
Python web app developers aren’t trusted to write applications that can run indefinitely. –> gunicorn eschews the two most common forking patterns in favor of a “fork-then-load” pattern that maximizes the ease with which an application can be reinitialized in the worker.
“Load-everything-in-parent-then-fork-without-exec” is very memory efficient, since the children processes all share a single copy of read-only memory. Gunicorn doesn’t use this pattern, because it would mean memory leaks and other code issues would require more complexity to fix than a quick reload in the child process. (The gunicorn documentation seems to dissuade users from loading the app before fork: “By preloading an application you can save some RAM resources as well as speed up server boot times. Although, if you defer application loading to each worker process, you can reload your application code easily by restarting workers.”)
“Fork-then-exec” is very safe, since the child process memory is completely replaced and you can’t accidentally get into deadlock. Gunicorn doesn’t use this pattern, because it would require spawning entirely new processes each time a worker child died, and process creation is pretty slow. (I’m still surprised by this, honestly; it’s not really that slow to create new processes, especially not compared to application lifetimes. Maybe I’m missing something.)
“Fork-without-exec-then-load” is what gunicorn opts to use. This approach uses more memory and it’s more dangerous, but it means reinitializing the user’s application each time something goes wrong is very lightweight.
Python is a scripting language in which all keywords are real statements that get executed, rather than some of them being declarations. –> It is possible to execute substantial amounts of code just by using the import keyword.
Configuring callbacks and other complex functionality is easiest if the config file is itself Python. –> In gunicorn, the config file can have side-effects. Nothing limits config to declaring parameter values.
Python and almost all its libraries are intended to run cross-platform. –> There are potentially bugs lurking in Python’s interactions with environments, because testing all code in all environment configurations is hard.
Everything interacts with everything else when you look deep enough.
Sherlock Holmes was my companion throughout this journey:
When you have eliminated the impossible, whatever remains, however improbable, must be the truth.
I investigated a number of wrong hypotheses along the way, from which I learned a ton – but this tale is quite long just covering what really was going on. I did not expect gunicorn in particular to work quite the way it does.
The spread of points in one dimension is easy to calculate and to visualize, but the spread of points in two (or more) dimensions is less simple. Instead of familiar error bars, standard deviational ellipses (SDEs) represent the standard deviation along both axes simultaneously. The result is similar to a contour line that traces the edge of one standard deviation, as on a topographic map or an isochore map. The calculation of a standard deviational ellipse can be tricky, because the axes along which the ellipse falls may be rotated from the original source axes.
The standard deviational ellipse algorithm is described here and here, and it was implemented in aspace, an R library for geographic visualization work developed by Randy Bui, Ron N. Buliung, and Tarmo K. Remmel. The SDEs are calculated by calc_sde and are visualized by plot_sde. (The people who are most interested in multi-dimensional standard deviations seem to be geographers visualizing point data; an example of visualizing auto theft in Baltimore appears at right.)
The aspace SDE implementation is a very useful implementation. I’m going to talk about implementing three extensions to it:
Giving better example code for how to use the package.
Fixing a bug in which the ellipse is often incorrectly rotated by 90 degrees. [This has been fixed by the authors in aspace 3.2, following contact from me.]
Adding a feature that shows more than one standard deviations.
This post addresses each in turn.
More Thorough Example Usage Code for aspace::plot_sde
plot_sde doesn’t take the result of calc_sde as a parameter, and its documentation doesn’t indicate how R knows which SDE to draw. To draw an SDE, run plot_sde immediately after calc_sde. R uses an implicit object hidden from the user to pass data. A better usage example is:
# Example aspace::calc_sde and aspace::plot_sde Codelibrary(aspace)
# Create the data and rotate itx =rnorm(100, mean =10, sd=2)
y =rnorm(100, mean =10, sd=4)
t =-pi/4# Illustrates normal case (rotated to right from vertical)#t = pi/4 # Illustrates the bug described below (rotated to left from vertical)transmat =matrix(c(cos(t),-sin(t),sin(t),cos(t)),nrow=2,byrow=TRUE)
pts =t(transmat %*%t(cbind(x,y)))
# Create the plot but don't show the markersplot(pts, xlab="", ylab="", asp=1, axes=FALSE, main="Sample Data", type="n")
# Calculate and plot the first standard deviational ellipse on the existing plotcalc_sde(id=1,points=pts);
plot_sde(plotnew=FALSE, plotcentre=FALSE, centre.col="red",
centre.pch="1", sde.col="red",sde.lwd=1,titletxt="",
plotpoints=TRUE,points.col="black")
# Label the centroid, explicitly using the hidden r.SDE object that was used in plot_sdetext(r.SDE$CENTRE.x, r.SDE$CENTRE.y, "+", col="red")
The above code will plot the data without axes, layering the SDE ellipse on top of a plot that does not display data markers (as illustrated at below right).
Correct Visualization Regardless of Major Axis
14 August 2012: This has been fixed by the authors in aspace 3.2 following contact from me.
The aspace 3.0 calc_sde code (accessible by typing the function name without parentheses at the R prompt) includes the lines:
This code seems to aim to ensure that theta is a positive number — but the first line doesn’t ensure that. Instead it causes negative rotations to end up at 90 degrees to where they should be (as in the illustration at right). Instead that first if-clause could be:
This code is one of multiple options that fixes the off-by-90-degrees issue.
Display of Multiple Standard Deviations
The aspace 3.0 calc_sde code only will only trace an ellipse of one standard deviation in each direction. To change this, add a multiplicative factor to sigmax and sigmay immediately before (or immediately after) the following lines:
if (sigmax > sigmay) {
Major <-"SigmaX" Minor <-"SigmaY"}
else {
Major <-"SigmaY" Minor <-"SigmaX"}
For instance, to calculate (and therefore plot) two standard deviations around the centroid, add in the lines:
sigmax=sigmax*2sigmay=sigmay*2
These lines double the length of the single-standard-deviation major and minor axes.
During standalone model installation, one user received an error that read “This directory cannot be written!” upon attempting to install the model into C:/Program Files/modelName. Creating the modelName directory directly in Explorer didn’t help, and neither did giving TrustedInstaller.exe (which is built into Vista) full permissions.
It seems like this may be an IzPack compatibility with Vista/Windows 7 issue (no guarantee, as I haven’t yet personally experienced or fixed this issue). (Repast uses IzPack to create the standalone .jar for model installation.) I haven’t been able to verify this myself yet, but am hoping the clue may be useful to others. It may be possible to overcome this error through settings within IzPack, a solution that I am only guessing is possible on the basis of a non-Repast thread at Stack Overflow — in that thread, the user solved the problem by making the installer ask for appropriate privilege escalation.
Drawing on that thread, apparently the issue here is a change in how post-Windows XP versions of Windows do administrator privileges. In Visa and Windows 7, you can be logged in “as an administrator”, but that doesn’t actually mean anything unless the UI/UAC confirms it (in reality on those OSs, running “as an admin” means you are actually running as a privileged user who can elevate to admin under appropriate circumstances). As a result, during install, the installer needs to know to pop up the UAC dialogue that queries the user whether s/he is okay with elevating for this task. The default Repast installer doesn’t allow for this.
You can also avoid this issue on Vista/Windows 7 by installing the model into a subdirectory of My Documents, should that be a possibility.
After creating new display items in the Repast runtime environment (a Data Set and a Chart) , I wanted to save the scenario so that Repast would remember to create these display items each time I ran the model. (When you click the Save Button/diskette in the runtime environment, the display items currently in the Scenario Tree are saved and then will always automatically load with the model — it saves a lot of work in recreating displays.)
But each time I clicked the diskette to save the model, I got this file not found exception:
2010/07/28 15:27:59,640: Error while saving scenario
java.io.FileNotFoundException: C:\Program
Files\RepastSimphony-1.2.0\workspace\yourModelName\yourModelName.rs\styles\.svn\all-wcprops (Access is denied)
at java.io.FileOutputStream.open(Native Method)
at java.io.FileOutputStream.(Unknown Source)
at java.io.FileOutputStream.(Unknown Source)
at repast.simphony.util.FileUtils.copyDirs(FileUtils.java:88)
at repast.simphony.util.FileUtils.copyDirs(FileUtils.java:81)
at repast.simphony.ui.RSApplication.doSave(RSApplication.java:420)
at repast.simphony.ui.RSApplication.save(RSApplication.java:376)
at repast.simphony.ui.action.SaveModel.actionPerformed(SaveModel.java:17)
(and so on)
And then suddenly my /yourModelName.rs/ folder (the one containing model.score) would be suddenly, horribly, inexplicably gone — which meant that running the model again was impossible until I reinstated it. (Repast was renaming the directory to /yourModelName.rs.bak/ and renaming any existing .bak files to .bak0, .bak1, and so on.)
At first I thought that the problem was a case of Repast moving /yourModelName.rs/ in expectation of generating a new version from my current runtime settings in its place, and then trying to copy previous data from the old filename (that no longer existed) rather than the renamed .bak version, but this is actually not what was happening. The FileNotFoundException wasn’t actually indicating a missing file (although by the time I got the exception, that file was indeed missing on that path)… it was indicating an unwriteable file.
In fact, for me, this was a Subversion-related problem. I was able to fix it by unsetting the read-only attributes on my .svn folders and their files and subfolders (both /yourModelName.rs/.svn and /yourModelName.rs/styles/.svn). I unchecked all the read-only checkboxes in the properties of those files. And then, magically, I could save the model scenario. Repast generated scenario.xml without any trouble once the .svn directory properties were changed.
I am unsure why this happened. Repast hasn’t complained about the other .svn directories in the project (which are all still marked as read-only). Other team members have not had this issue. I was able to successfully save scenarios earlier this year. But in any event, lesson learned and solution found.
What’s this blog about?
Whatever is on my mind. The content has varied over the past more-than-decade, but it's always been technical. In the early years I focused on improving the fabric of the internet for some niche tools. But the internet no longer needs that kind of improving, and search doesn't really work like that anymore either. This blog is currently mostly about documenting notes for my future self, and sharing those notes with anyone who is interested.